大名鼎鼎的分布式版本控制软件git,由于其免费开源,拥有诸多独特的优点,非常的流行。 git的上手很快,去网上找一些基本的教程就能开始拿它管理自己的代码了。
可是,一旦用到一些比较深入的用法,上网去查命令,就觉得命令很奇怪。比如说:
- git reset不是回退版本吗?为什么能够用来撤销stage?
- git checkout不是用来切换分支的吗?为什么用
git checkout -- <file>撤销代码的改动? - 为什么有的时候直接执行
git push能成功?为什么有的时候却给你一堆提示信息?
如果把git当成一个用户软件,它的用户使用模型抽象的确有点儿晦涩。 实际上,我觉得git根本就没有针对用户设计一个简单的使用模型来屏蔽内部的复杂性,git直接把git内部的组织模型暴露给了用户。 因此,想要真正理解git,就必须要理解git的内部组织模型。好在,git的用户多是程序员,理解它并不是很困难。
1. git组织方式
git 管理代码仓库,是将其分为四个部分:
- 远程仓库(remote repository)
- 本地仓库(HEAD/local repository)
- 暂存区(INDEX/stage)
- 工作区 (Local directory)
关于工作区,stage,本地仓库的概念图如下:
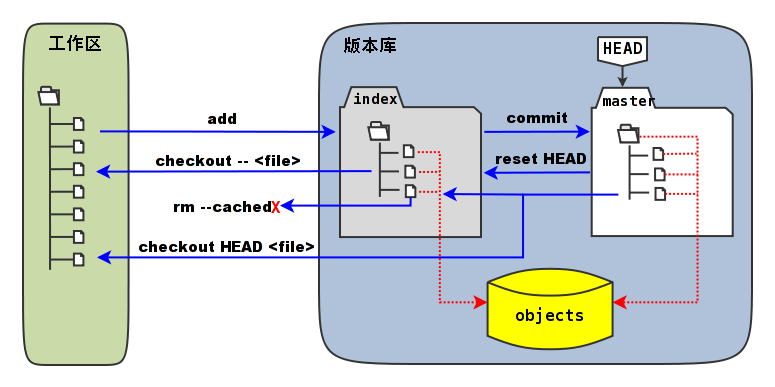
2. 工作区
梳理下新建git仓库的过程。假设现在我有代码放在 code/project/ 目录下:
|
|
git init 命令会将这个目录建立起一个本地仓库。 这其中, code/project/ 目录就称为 工作区 。 你对代码的修改更新等操作都是直接修改这个目录里的代码的。 比如啊,在这个目录也就是工作区给代码加了个功能,之后把这些更新的代码用git命令保存到本地仓库里去。 在 本地仓库 里,把各个时间的旧代码根据时间顺序串起成一条线,用以记录代码的开发过程。
仔细观察会发现,新建git仓库后,会发现目录里面多了个隐藏目录 code/project/.git 。git一切对这个仓库的信息都保存在这儿。 看上面的那张图,其中暂存区,本地仓库等信息被一个蓝色的框框了起来,这些信息就储存在 .git 下。
由于这个特点,git仓库非常的”绿色“。你把它拷到另一个目录里,照样可以用git去正常操作它。
3. 缓存区(stage)
现在,在 工作区 加了些新代码,给产品开发了一个新功能。 现在,要把这个最新的代码记录到本地仓库里去,众所周知:
|
|
让人很疑惑的是,为什么git设计里不直接 git commit 就能提交工作区代码,而非要加个貌似多余的 git add 命令?
3.1. 一次提交只干一件事
实际上,使用版本控制软件管理代码,一个良好的习惯是, 一次提交只干一件事 。 比如:添加了一个新功能,修改了一个bug等等。 这样,整个代码的开发过程被管理的井井有条。而不是新功能的部分代码和修复bug的部分代码混在一起,很混乱。
可是实际写代码的时候,有可能同时进行了多项改动。比如添加一个新功能的时候又修复了一个bug。 假设我们修复了 lib.c 里面的bug,然后在 main.c 里面添加了一个新功能。
如果git提供的功能只能对工作区的改动一把提交,明显就违背了 一次提交只干一件事 的原则。
3.2. stage的作用
这样, 暂存区(stage) 的价值就体现出来了。 每次对文件改动,都需要使用 git add 将其添加到stage。 在stage积累了一批改动后,然后再将stage的内容提交到本地仓库。 git add 命令:
git add lib.c将lib.c文件添加到stagegit add .常在工作区根目录下执行,将所有的改动添加到stage。 (看网上说无法处理删除文件的情况,但是在我的git版本里能够正确处理,可能是git新版本修复了这个问题)git add -p这个命令更厉害。它能够让你对同一文件里的改动进行挑选,选择哪些改动需要添加到stage
从开头的那张图里,很清楚的看到git提交的流程: 工作区 —> stage —> 本地仓库
最后,使用 git commit 命令将stage里面内容提交到本地仓库。
3.3. git status
理解了stage的概念, git status 命令的输出也就很好理解了。
比如说,现在,修改一个文件( README.md ),然后 git add 加入到stage。 此时,stage里的内容就和本地仓库里相比有所改动。
之后,再修改下这个文件。此时,工作区里的内容相比stage也有所改动。
这时,尝试使用 git status -s 会发现输出类似这样(-s可以得到更紧凑的结果):
|
|
注意到前面的两个M:
- 第一个M表示,本地仓库(HEAD指针)中的文件和stage中的
README.md文件相比有改动 - 第二个M表示,工作区当前的文件和stage中的
README.md文件相比也有改动
可以看到, git stauts 的命令,是显示工作区的文件情况。它可以指出工作区的哪些文件有所改动。
4. 本地仓库
4.1. 提交(commit)
每次将stage里的一个代码版本提交到本地仓库里,这称为 提交(commit) 。 每个提交(commit)都有对应的一个唯一id,这是sha1哈希值。 由于git是分布式的版本管理软件,因此git用sha1哈希值来标识commit,以避免冲突。
每次提交时,上次的commit(准确的说是HEAD指向的commit)就成为了这次commit的父提交。 按照这个顺序给串起来,就形成了一条线(由于git支持分支,准确的说是个图)。用下面的命令就能直观看到:
|
|
4.2. HEAD指针和master分支指针
git既然是作为版本管理软件,自然是能在各历史版本之间切换的。
因此,除了上面介绍的时间线,git还有一个称为 HEAD 指针的东西。
如下图所示, HEAD 指针指向 master分支 指针, 而 master 分支 指针指向 commit cc78fa。
|
|
在进行的新的commit(提交)时,是以HEAD指向的commit作为其父提交的。
上面所说的 master分支 是服务于git的分支功能的。
4.3. 时光穿梭,回到过去
既然git的本地仓库记录里各历史提交,那我当然也可以将代码版本回退到历史上的某次提交上去。
回退历史的命令是 git reset :
|
|
其中HEAD 表示HEAD指针指向的commit。 这个命令会:
- 假设当前分支(HEAD指向的分支)是
master,移动master指针到指定的commit - 把指定commit的内容拷贝到stage
- 把指定commit的内容拷贝到工作区
看,成功回退到了历史版本!
实际上,带 -hard 参数的 git reset 命令会移动分支指针并且更新stage和工作区。
除了 --hard 参数外, git reset 命令还有 --mixed 参数 和 --soft 参数:
git reset --softed <commit>只移动分支指针,但是不更新stage和工作区。git reset --mixed <commit>移动分支指针,更新stage但是不更新工作区。git reset <commit>同上,默认是--mixed参数。
git reset 还有一种对文件的用法:
|
|
很显然,我们可以这样理解这个命令,首先会将当前分支指针移动到HEAD指向的commit。 由于当前分支指针和HEAD指向的commit是同一个,所以相当于什么都没做。 我们真正需要的是第二步,它还会把HEAD指向的commit里记录的文件版本复制到stage里面来。
因此,这个命令其实达到了撤销stage里的文件的效果,相当于 git add 命令的反向操作。
4.4. 时光穿梭(回到未来)
刚才,你切换到历史的某次提交。
问题是,我现在又想回去了。由于 git reset 命令需要commit id,因此我得先找到原先那次提交的commit id。 试图执行 git log 查询之前的commit id,发现看不到了!
不要慌,由于git记录分支指针指向的变迁。 因此,可以执行 git reflog show master :
|
|
好了,现在能找到你需要的commit id了。
要注意的是:
- reflog来自的信息仅仅是本地仓库
- 如果一个commit没有被任何分支跟踪到,那当reflog中含有该提交的日志过期后,这个提交随时都会从版本库中彻底清除。
4.5. 分支
前面提到了,git本地仓库存在一个HEAD指针和master分支指针。 HEAD指针指向master分支指针,代表当前的分支; master分支指针指向某个commit,代码该分支所在的commit。 是不是有种学习数据结构的感觉?没错了,其实这就是git内部组织本地仓库的数据结构的一部分。
使用 git branch test 就能创建一个分支名为 test 。这样就多了一个test分支指针:
|
|
切换分支的命令是:
|
|
它做了两件事:
- 将HEAD指针指向test分支指针
- 将test分支指针指向的commit的内容复制到stage和工作区
git分支是很轻量的,创建分支,仅仅是创建了分支指针而已;而切换分支,也仅仅是移动了分支指针,然后更新下stage和工作区而已。
git checkout 称为 检出 操作。 这个命令还有另外一种用法:
|
|
这种用法不会移动HEAD和分支指针。它会把
假如
|
|
相当于撤销工作区里的改动。
5. 远程仓库
5.1. 别名
使用命令:
|
|
给远程仓库的地址origin 。
使用以下命令就能看到记录的远程仓库:
|
|
5.2. 远程分支
现在来聊一聊有关分支的事情。我们知道,使用 git branch 命令能够查看所有的本地仓库的分支。
那试一下下面的命令?
|
|
会看到类似下面的输出:
|
|
这些分支都是以 origin/ 开头,这些分支实际上是位于远程仓库origin里面的,但是在本地也会存有一份引用。
如果我们执行命令:
|
|
git会将远程仓库origin上的最新情况同步下来,反映到本地就是 origin/ 开头的一系列远程分支的信息发生了变化。
5.3. 推送和拉取
以 origin/ 开头的远程分支只是远程仓库分支的一份引用,在本地进行的提交等活动只能在本地分支上进行。 那如何将本地分支上的改动同步到远程分支上去?执行以下命令:
|
|
这个命令会把 本地分支 develop 上的提交推送到远程分支 origin/develop 上去。 可以看出,它会把本地的指定的分支推送到远程仓库的同名分支上去。
那如何把远程分支 origin/develop 上的提交同步到本地分支 develop 上来呢? 首先你的当前分支是 develop ,同样,执行:
|
|
反过来,它会把远程分支 origin/develop 上的内容拉取到当前分支,也就是 develop 上来。
它相当于:
|
|
第一条命令是将远程仓库origin的所有改动拉取下来, 本地的远程分支的信息会发生变动。 第二条命令是将远程分支 origin/develop 合并到当前分支,也就是 develop 上来。
5.4. 分支跟踪
假设远程仓库origin上有个分支叫develop。但是本地分支没有。 我用以下命令创建 develop 分支:
|
|
输出信息里的 跟踪 是什么意思? 从字面信息来看,是本地分支 develop 跟踪 了远程分支 origin/develop 。 可是有什么用呢?
假设现在的当前分支是 develop , 试试不带参数的git push:
|
|
你会惊讶的发现,推送成功了。实际上,它会根据当前分支的跟踪信息,把当前的本地分支推送跟踪的远程分支上。
同样,不带参数的 git pull:
|
|
也是将当前分支跟踪的远程分支拉取到当前分支上来。
6. 感谢
虽然用git这么长时间了,但是一直也只会用几个常用的操作。 然而我经常不理解为什么有的命令能够做到这样的效果,这和我心里想当然的模型不符合。 所以一直我都有一种不舒服的感觉,我认为自己根本就没有理解git的模型。
幸运的是,前几天发现了一本好书,在这里就可以免费阅读: http://www.worldhello.net/gotgit/
这本书深入到了git的内部实现,剖析了git的内部设计。 花了几个小时通读完第2和第3章,顿时感觉恍然大悟,茅塞顿开! 只后再去重新审视一下git各命令,怎一个爽字了得,哈哈!
当然,我个人认为,这本书讲的有些细,深入到了内部实现情况。实际上想要理解git,深入到git的内部设计模型就足够了。 最后感谢那本书的作者,花了大量时间把如此宝贵的经验与大家免费分享,即使放到图书的书架上,这也是不可多得的一本好书,值得掏钱购买。