毕业两个星期了,开始成为一名正式的java码农了。
一直对偏底层比较感兴趣,想着深入自己的java技能,看书、读源码、总结、造轮子实践都是付诸行动的方法。
说到看源码,就应该由简入难,逐渐加深,那就从jdk的源码开始看起吧。
ArrayList和Vector是java标准库提供的一种比较简单的数据结构,也是最常用的一种。
1. 线性表的概念
1.1. 表ADT
表这种抽象概念指的是一种存放数据的容器,其中数据A1, A2, A3, …, Ai, … AN有序排列。
那么在表这一抽象的数据结构模型中:
- 数据是有序排列的,有前后之分。
- 表中每个数据都有一个索引,A1元素的索引为0, Ai元素的索引为i - 1。至于索引从0开始还是从1开始编号这个不是重点。
- 表的大小为即为数据的个数,即N。
它的操作有:
- 获取表的大小。
- 取出表中给定索引的数据。
- 给表中给定索引的位置放入数据。
- 向指定位置插入数据。
- 将指定位置的数据移除。
表有两种实现方式,数组实现和链表实现。这两种实现方式各有优劣,其中这里所说的ArrayList是数组实现方式。
1.2. 实现思路
线性表的实现中是将元素放到数组中的。如果是C的数组,那其实是一块连续的内存。
在java中也是java的原生数组,内存布局中逻辑上是连续的,物理上不一定。印象中有的jvm实现为了解决内存碎片搞类似逻辑内存的这种操作。
往线性表取出数据或拿出元素都能很直接对应到原生数组中去。
但是,线性表插入数据的这一操作要求表是能够动态增长的,但是原生数组的大小是固定的。
线性表实现的一大重点是实现表动态增长这一要求,将其转换、化归到固定大小的原生数据上去。思路是,当线性表内部保存数据的数组如果不够用了,就申请一个更大的数组,将原来数组的数据拷贝进去。
1.3. 时间空间复杂度
- 由于线性表用数组实现,因此定位元素实际上只需要计算内存偏移量即可访问得到,取出和放入元素的时间复杂度为O(1)。
- 由于数组中的元素是紧密排列的,因此在中间插入一个元素或移除一个元素需要移动后面一排数据,所以往指定位置插入或移除数据的平均时间复杂度为O(n)。
- 如果是往表末尾插入元素,情况比较复杂因为这可能触发扩容操作。不触发扩容就是O(1),如果触发了扩容,假设是2倍扩容,我们可以把扩容的时间均摊到前面每一个元素的插入操作上,平均来说,也是O(1)。
2. ArrayList的继承结构
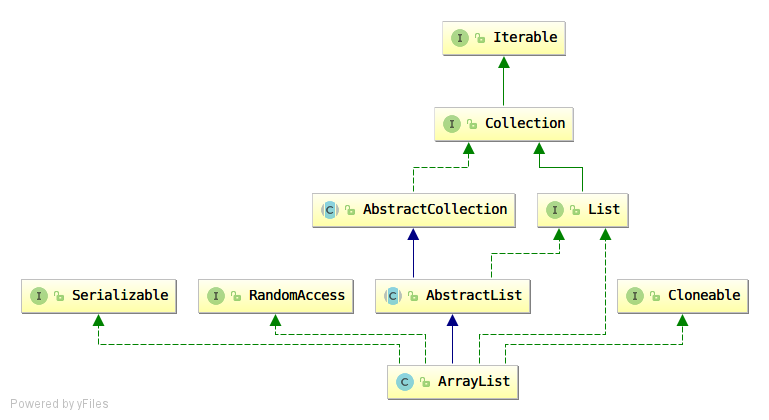
如上图所示,在设计上,它的结构应该理解成 ArrayList –> List –> Collection –> Iterable:
List接口表示抽象的表,也就是上面所说的表。Collection接口表示抽象的容器,能放元素的都算。Iterable接口表示可迭代的对象。也即该容器内的元素都能够通过迭代器迭代。
但是在继承结构上,ArrayList继承了AbstractList。这是java中通用的一种技巧,由于java8之前的接口无法指定默认方法,如果你要实现List接口,你需要实现其中的所有方法。
但是,List接口中的所有方法是大而全的,有大量方法是为了方便调用者使用而设计的衍生方法,并非实现该接口的必须方法。比如说,isEmpty方法就可以化归到size方法上。
所以,java对于List接口会提供一个AbstractList抽象类,里面提供了部分方法的默认实现,而继承该类的只需要实现一组最小的必须方法即可。
总而言之一句话,AbstractList的作用是给List接口提供某些方法的默认实现。
3. ArrayList源码分析
3.1. 属性
先看ArrayList内部保存的属性和状态。
其中,最关键的为elementData和size。 elementData也即真正存储元素的java原生数组。
由于ArrayList中实际保存的元素个数是少于elementData数组的大小的,也即会有部分空间的浪费,因此size属性是用来保存ArrayList存储的元素个数。
值得注意的是,elementData没有访问修饰符,我们知道默认是对包内可见的。这样做的目的是:
- 即能保证使用者(包外)无法访问到这个属性,保证了数据隐藏;
- 另外一方面,实现ArrayList需要一些辅助作用的嵌套类,它们需要知道部分ArrayList的实现细节。由于它们和ArrayList在同一个包下,这样辅助类能够访问到它们。
3.2. 构造函数
构造函数一共有三个,下面是其中两个。第三个是从其它容器初始化,没什么好看的地方。
第一个带参数的构造函数,行为上这个都知道,创建出来的依然是个空表,看代码也可发现执行完后size属性为0。initialCapacity的含义是指定内部存储数据的原生数组的初始化大小。
代码逻辑很简单,initialCapacity大于0时对elementData分配该大小的原生数组。但是问题是,initialCapacity为0时,并不是直接new一个大小为0的数组,而是使用静态变量EMPTY_ELEMENTDATA来代替。
为什么?EMPTY_ELEMENTDATA是静态变量,所有实例共享,个人猜测应该是为了省点内存吧。可是这个占不了多大的内存啊,这个理由可能说服力不太强。
第二个默认构造函数,这个函数行为上也是创建空表。但是会预先将存储数据的原生数组的大小设置为DEFAULT_CAPACITY,也就是默认值10。这样,能避免在大小较小时频繁扩容带来性能损耗。
按照这个思路,代码应该长这样才对:
但是实际上,我们发现DEFAULTCAPACITY_EMPTY_ELEMENTDATA其实是个空表,也是静态变量,多实例共享的。
这实际上也可以认为是一种优化手段,因为很多场景都是直接默认构造的一个空表在哪里放着,为了节约内存,jdk实现先不实际分配空间,仅仅做一个类似标记作用的操作,之后真正使用了才会分配空间,达到一个类似“延迟分配”的效果。这些思路在扩容相关的代码中有所体现。
3.3. get和set
get和set没什么好说的,实际上是直接操作内部的原生数组。
不过,从下面的代码中可以看到,在get和set之前,会做越界检查。
3.4. add
下面再来看插入元素。插入有两种:
- 第一种是在末尾插入。
- 第二种是在中间插入。
|
|
思路都特别显然,主要是在操作之前,调用了ensureCapacityInternal函数,这个函数调用完毕后会保证内部数组的空间能存储下这么多元素。
此外,void add(int, E)函数还做了越界检查。
3.5. 扩容操作
接下来看ensureCapacityInternal函数,相关实现涉及到四个函数。
这个函数的目的是保证执行完后,内部的原生数组至少能容纳minCapacity个元素。
之前所说的那种“延迟分配”操作在这里就体现出来了。分析代码流程不难发现,当elementData为DEFAULTCAPACITY_EMPTY_ELEMENTDATA,也即前面所说到的那个标记,那么之后扩容后的原生数组空间一定不小于DEFAULT_CAPACITY,也就是前面定义处的10。
再看具体的扩容逻辑,也即grow函数。逻辑还不单一。首先扩容尝试按照原来大小的1.5倍扩容,为了性能,这里除以2优化成了右移运算。
如果1.5倍不够怎么办?如果是我,我可能会优雅的递归再扩大,然而,jdk的做法是如果1.5倍不够的话直接按照需要的大小扩容。
最后,如果实在太大,也要做一下限制,最大可达到的大小为Integer.MAX_VALUE,否则就超过了int的范围,溢出了。
3.6. 移除操作
下面是移除相关的函数,有两个:
E remove(int)是通过索引移除。boolean remove(Object)是通过元素移除。
|
|
按索引移除的的思路很简单,首先把需要移除的元素拿出来,然后后面的都往前挪一个,通过数据拷贝实现。
但是,有个 特别需要注意的地方是,假设删除之后的表大小为N,往前挪一个后,elementData[N - 1]和elementData[N]都指向了最后一个元素。这时elementData[N]仍然持有对该元素的引用。如果之后试图移除表中最后一个元素,它可能不会及时的被gc干掉,造成无意义的额外内存占用。
按元素移除的思路也很显然,先是找到该元素的索引,然后按索引移除。fastRemove的代码几乎和remove(int)一模一样,不知道为什么复用一下。。。
最后,从代码可以看到一点,表内元素会被移除,但是jdk对ArrayList的实现只会扩容表,而不会缩小表以减小内存占用。不过,它提供了一个trimToSize方法,将表中原生数组的空闲空间去掉:
很明显,它重新分配一个正好合适的原生数组,然后拷贝过去。
3.7. removeAll&retainAll
这两个函数很好理解:
- removeAll是移除所有c中的元素
- retainAll是保留所有c中的元素
这两个函数算法几乎一模一样,因此抽象出一个函数batchRemove来实现。
|
|
核心在于try中的那三行代码。这个算法简化了就是这样:
有两个数组data和isRemove,isRemove[i]为true表示data[i]应该被移除。
要求在O(n)时间复杂度,O(1)空间复杂度,将data中isRemove[i]为true的元素移除。
算法这种东西,思路我能在脑子里想象出来画面,但是说不清楚。。。
![]() 大学里学习算法时候都写过,就不多说了。
大学里学习算法时候都写过,就不多说了。
3.8. 其它
感觉写的有点多。。。以上是和ArrayList操作密切相关的,其它的简单总结下吧。
- subList. subList返回的是一个List,代表着该ArrayList的中间一段。这个subList实际上返回的是类似视图的对象,它本身不存储数据,所有的对subList的操作最终会反映到原来的那个ArrayList上来。实现在辅助类
SubList中。 - iterator. 返回迭代器,与之有一个搭配的辅助类
Itr。基本都是一些包装代码。 - sort. 排序是通过调用
Arrays.sort实现的,所以,具体的排序算法要看Arrays.sort。
还有一个没有看懂的问题,即在AbstractList中有一个modCount字段,ArrayList的实现中多次操作该字段。但是仍然没有理解该字段的作用。
4. Vector
Vector提供的容器模型和ArrayList几乎一模一样,只不过它是线程安全的。
它的代码思路上和ArrayList差不多,但是有一些实现细节上的小区别。
首先,它有一个参数capacityIncrement,能够控制扩容的细节,看构造函数:
如果不指定的话,这个initialCapacity默认值为0。在内部使用属性capacityIncrement保存。
其次,再看控制扩容的核心函数grow,研究下扩容逻辑是不是有什么差异:
可以发现,capacityIncrement控制的是扩容的步长。
如果没有指定步长,那么则是按照两倍扩容,这是与ArrayList不同的地方。
总体上,它相当于synchronized同步过的ArrayList,也即它对线程安全的实现非常暴力,并未用到太多的技巧。很显然,在并发环境下,对vector的操作直接锁住整个vector,相当于操作vector的线程是串行操作vector,性能不高。