链表是对上一篇博文所说的顺序表的一种实现。
与ArrayList思路截然不同,链表的实现思路是:
- 不同元素实际上是存储在离散的内存空间中的。
- 每一个元素都有一个指针指向下一个元素,这样整个离散的空间就被“串”成了一个有顺序的表。
从链表的概念来讲,它可以算是一种递归的数据结构,因为链表拿掉第一个元素剩下的部分,依然构成一个链表。
1. 时间空间复杂度
- 通过索引定位其中的一个元素。由于不能像ArrayList那样直接通过计算内存地址偏移量来定位元素,只能从第一个元素开始顺藤摸瓜来数,因此为O(n)。
- 插入元素。实际上插入元素需要看情况:
- 如果指定链表中某个元素将其插之其后,那么首先得找出该元素对应的节点,还是O(n)。
- 如果能够直接指定节点往其后插入(如通过迭代器),那么仅仅需要移动指针即可完成,O(1)。
- 移除元素。移除和插入类似,得看提供的参数是什么。如果提供的是元素所在的节点,那么也只需要O(1)。
2. LinkedList的继承结构
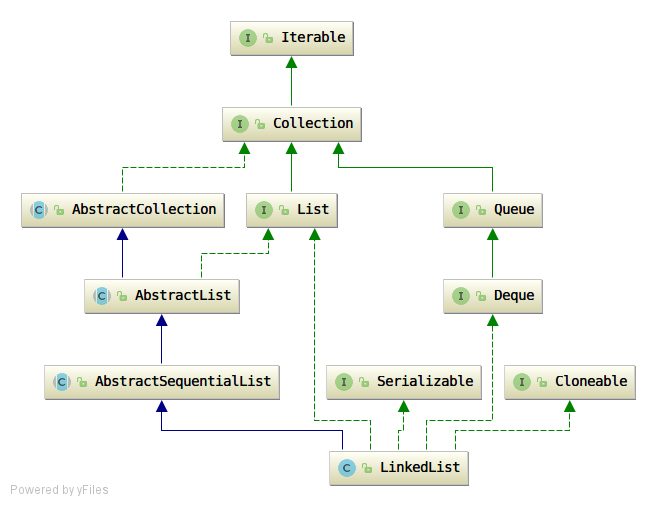
首先继承结构和ArrayList类似,实现了List接口。
但是,它继承的是继承了AbstractList类的AbstractSequentialList类,
这个类的作用也是给List中的部分函数提供默认实现,只是这个类对链表这种List的实现提供了更多贴合的默认函数实现。
还有可以注意到,LinkedList实现了Deque接口,这也很显然,链表这种结构天然就适合当做双端队列使用。
3. LinkedList源码分析
3.1. 节点定义
先来看链表的节点定义:
可以看到,链表节点除了保存数据外,还需要保存指向前后节点的指针。
这里,链表即有后继指针也有前驱指针,因此这是一个双向链表。
一组节点之间按顺序用指针指起来,就形成了链表的链状结构。
3.2. 属性和构造函数
|
|
三个属性,first和last分别指向链条的首节点和尾节点。
这样有个好处,就是链表即可以使用头插法也可以采用尾插法。
size属性跟踪了链表的元素个数。虽然说遍历一遍链表也能统计到元素个数,
但是那是O(n)的费时操作。
因此,我们可以发现链表的size方法是O(1)的时间复杂度。
|
|
LinkedList的代码很简单,构造函数空空如也。
空表中,first和last字段都为null。
3.3. get和set方法
|
|
get和set的思路都是先根据索引定位到链表节点,然后获得或设置节点中的数据,这抽象出了node函数,根据索引找到链表节点。
node的思路也很显然,遍历一遍即可得到。
这里做了一点优化,我们可以发现LinkedList的实现是一个双向链表,并且LinkedList持有了头尾指针。
那么,根据索引和size就可以知道该节点是在链表的前半部分还是后半部分,
从而决定从头节点开始遍历还是从尾节点开始遍历,这样最多遍历 N / 2次即可找到。
4. 添加/删除
|
|
添加/删除的思路都类似,删除的代码就不贴了。如果能够提供需要被操作的节点,就能直接移动下指针,O(1)完成。否则就需要遍历找到这个节点再操作。
需要关注两点:
- 有的操作是操作头指针,有的操作是操作尾指针。但是不管操作哪一个,都需要维护另外一个指针及size的值。
- 如果是删除,删除后及时把相关节点的item字段置为null,以帮助gc能更快的释放内存。
5. modCount字段分析
之前阅读ArrayList的代码时发现了modCount这一字段,它是定义在AbstractList类中的。之前不知道它起到什么作用,这次给弄明白了。
5.1. 迭代器
5.1.1. 迭代器迭代中表被修改
考虑以下这段代码:
在迭代器创建之后,对表进行了修改。这时候如果操作迭代器,则会得到异常java.util.ConcurrentModificationException。
这样设计是因为,迭代器代表表中某个元素的位置,内部会存储某些能够代表该位置的信息。当表发生改变时,该信息的含义可能会发生变化,这时操作迭代器就可能会造成不可预料的事情。
因此,果断抛异常阻止,是最好的方法。
实际上,这种迭代器迭代过程中表结构发生改变的情况,更经常发生在多线程的环境中。
5.2. 记录表被修改的标记
这种机制的实现就需要记录表被修改,那么思路是使用状态字段modCount。
每当会修改表的操作执行时,都将此字段加1。使用者只需要前后对比该字段就知道中间这段时间表是否被修改。
如linkedList中的头插和尾插函数,就将modCount字段自增:
5.3. 迭代器
迭代器使用该字段来判断,
|
|
迭代器开始时记录下初始的值:
然后与现在的值对比判断是否被修改:
这是一个内部类,隐式持有LinkedList的引用,能够直接访问到LinkedList中的modCount字段。